

On this page
How much energy does AI use?
A summary of the key facts from the real environmental cost of the AI race article.
Energy consumption and growth
- Data centres account for 1.5% (415 TWh) of global electricity demand in 2024, with AI representing around 10% of this demand
- By 2030, data centres are projected to reach 3% (975 TWh) of global electricity demand in the base scenario, representing a 15% annual increase – four times faster than other sectors
- In mass adoption scenarios, AI could account for 50% of data centre electricity consumption by 2030, representing a 5-10x acceleration compared to 2022
Training vs usage (inference)
- Training GPT-4 required three months of calculation on 25,000 GPUs and consumed approximately 50 GWh
- For popular generative AI models with around 100 million uses, the inference phase becomes more energy-intensive than initial training – this threshold is reached in just a few hours on ChatGPT, which now has at least 1 billion requests per day
- Around 80% of electricity consumption in data centres is reserved for inference (daily use) rather than training
Comparative energy costs by task
- Generating text is on average 25 times more energy-consuming than classifying text
- Generating an image is on average 60 times more energy-intensive than generating text, consuming about 1-3 Wh per image
- Generating a 6-second video at 8 frames per second requires about 115 Wh, equivalent to charging two laptops
Carbon emissions
- Data centre emissions currently represent 180 million tonnes of CO2 and are projected to increase to 300 Mt by 2035 in the base scenario, and up to 500 Mt in the mass adoption scenario
- Many coal-fired power plants are having their closure dates postponed to meet data centre demand, and 44 GW of new gas projects worldwide have been identified specifically to meet data centre needs
Water consumption
- The International Energy Agency expects water consumption from data centres to double by 2030, reaching 1,200 billion litres
- Between 2019 and 2023, water consumption at Virginia’s data centres increased by more than 60%
Local impacts and conflicts
- Data centres can cause network overloading, dangerous voltage fluctuations, disruptions in electricity quality, and network instabilities, with wait times to connect new data centres extending to 7-10 years in some US jurisdictions
- In the eastern United States, monthly electricity bills increased by an additional $10 to $27 per month in summer 2025 due to increased AI demand
- Generative AI could generate up to 5 million tonnes of additional electronic waste by 2030, in addition to the 60 million tonnes produced today
The transparency problem
- 84% of language model usage involves models without any environmental transparency, and AI suppliers reveal almost no reliable information about consumption for reasons of competitiveness, security, and reputation
- The widely cited claim that “a ChatGPT query equals 10 Google searches” traces back to an off-hand remark by Alphabet’s president in 2023, not verified data
The real environmental cost of the AI race
Lou Welgryn and Théo Alves Da Costa published a primer about AI’s environmental cost in Bon Pote. This is the English translation of that article.
“AI and the success of the energy transition go hand in hand. We will not see a large-scale transition to carbon-free energy without the significant advances that AI promises to bring.”
This quote from Mélanie Nakagawa, Microsoft’s head of sustainability in February 2025, reflects the magical thinking that is increasingly found in the media and society. That of a mystical and providential AI that would be the solution to all our problems, and that would justify its unbridled development since the arrival of ChatGPT in 2022.
While Emmanuel Macron announced in February 2025 private investments of 109 billion euros to develop AI and more than 35 new data center projects have been announced in France, we offer an in-depth analysis to deconstruct these speeches and discover the hidden face of artificial intelligence.
As AI researcher Kate Crawford summarizes, she relies on a triple extraction: natural resource extraction, data extraction, human exploitation. In this article we will focus on the direct environmental impacts of AI (energy consumption, carbon emissions, local impacts of data centers), but insist on the need to understand these technologies as a whole to understand the societal upheavals that its massive adoption generates (power issues, mass surveillance, militarization, social inequalities, etc.)
We will start by defining what artificial intelligence is, its recent evolution, the actors that underlie it and detail the particular functioning of generative AI. Then in a second step we will describe the physical infrastructure that supports it.
Far from floating above all physical reality, as the lexical field of the “cloud” and “dematerialization” likes to make us believe, these technologies have very tangible material consequences.
What is Artificial Intelligence?
Let’s start by defining the terms. The technical definition of artificial intelligence is the ability of software, via algorithms, to perform and emulate tasks typically associated with human intelligence, such as learning, reasoning, problem solving, perception or decision-making. It is important to understand that there is not artificial intelligence but desartificial intelligence, and that they have been present in our daily lives for much longer than we think.
The Dartmouth conference in 1956 launched artificial intelligence as a field of research in its own right. The term Artificial Intelligence is even chosen in relation to other expressions like Automata Studies for marketing reasons more likely to attract financing.
Since then, the history of AI has seen twists and disappointments in the face of the commercialization potentials of this technology. Since the 2010s, the field has experienced a new wave of scientific and industrial interest for at least 4 reasons: a large amount of data available to feed the algorithms following the advent of social networks and digitalization, more computing power, and unprecedented investments based on the repeated promises of revolutionary technology self-powered by tech giants and states.
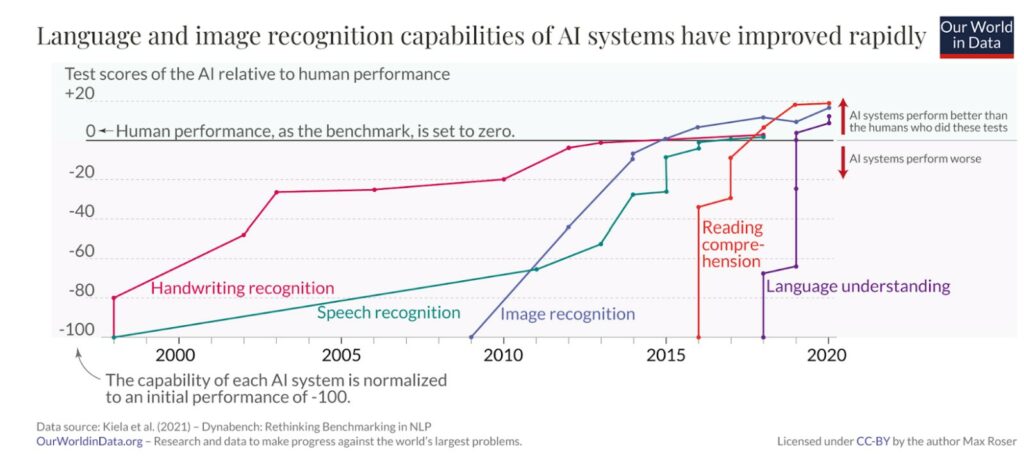
For example, as shown by this graph tracing the performance of AI systems compared to those of humans on specific tasks, AI systems have gradually become effective at handwritten recognition (such as transcribing amounts on a check), then on voice recognition, then on image recognition (for example to recognize a passer-by on a camera, a face to unlock his phone, or a monument in a photo of social networks)
Improved performance on these specific tasks has accelerated over the past two decades.
The Age of Generic AI since ChatGPT’s release in 2022
If Artificial Intelligence is a field of research and engineering that has existed for almost 80 years, since 2022 we have entered a new era: that of the explosion of generative AI – symbolized by the opening to the general public of ChatGPT in November 2022. To understand the environmental impacts of AI, it is important to understand the difference between AI families and what this recent wave of generative AI has in particular.
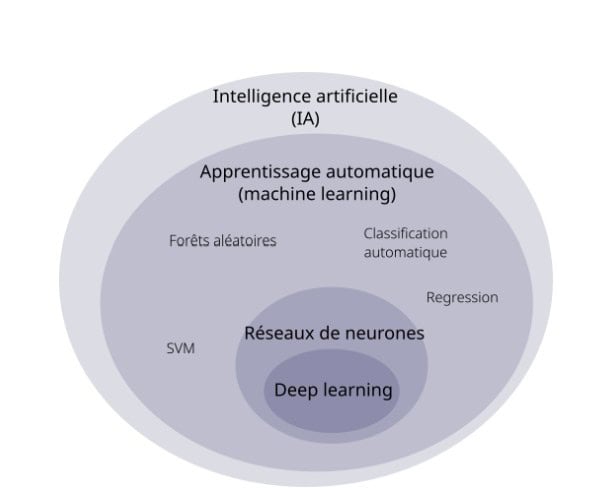
The Machine Learning
Since the 2000’s, when we talk about AI it is mainly to talk about machine learning, that is to say a computer program that learns from examples rather than being explicitly programmed with rules. For example, in the context of a translation, rather than writing all the possible rules to translate a text from French to English (conjugation, grammar, dictionaries of words, …) the algorithm will “read” the same texts in French and English and “discover” the complex rules to move from one language to another without necessarily explaining them. It is important to specify here that there is nothing intelligent or autonomous: the explanation is simplified to popularize the operation (quotes on “read” and “discover”), but it is in reality a calculation of probabilities that is carried out.
It is thanks to this new computer paradigm that translation software no longer translates word for word.
Deep Learning and LLM (Large Language Models)
Machine learning is also a large family of algorithms with dozens of possible mathematical techniques. One of them is deep learning, which consists in using a mathematical modeling called “artificial neural networks”, very vaguely inspired by the functioning of our brain.
In 2017 Google’s search teams publish a search paper “Attention is all you need” that offers a new mathematical technique for deep learning: the Transformers (the famous T of ChatGPT). This technique will accelerate the construction of general AI algorithms, i.e. not dedicated to a single task, thanks to what is called self-learning or pre-training. These algorithms are often called Large Language Models or LLMs (large language models)). Let’s take an example: automatically sort an email in spam and translate a text from French to English, two tasks that have nothing to do with it. However, both use an identical underlying problem: understanding language and analyzing a text. Self-learning will therefore consist in showing a massive amount of texts to statistically model the functioning of the language (vocabulary, syntax, grammar, expressions). In 2019, a still unknown “non-profit” laboratory called OpenAI then released the GPT-2 algorithm (for General Pretrained Transformers). GPT-3 is released in 2020 and shows results that impress researchers and the general public; the model is 100 times larger than the previous version.
In November 2022, OpenAI launched ChatGPT and triggered the new wave of consumer generative AI. If generating synthetic content (text, image, sound…) is therefore not new, what will be decisive with ChatGPT is the conversational interface (with the prompts) and a specialized model for the conversation thanks to a technique called RLHF (Reinforcement Learning from Human Feedback), where human annotators classify and improve the responses of the model, mainly Kenyan employees experimenting with working conditions and very precarious remuneration.
The extent of this adoption is dizzying. ChatGPT reached 400 million weekly active users in February 2025, after conquering its first million users in just 5 days – an adoption speed 12 to 60 times faster than popular social media apps. In the United States and the United Kingdom, 40% of households now use these tools, while in countries such as Brazil, India, Indonesia, Kenya and Pakistan, more than half of internet users use generative AI at least once a week. Corporate adoption is the same fast pace: among the major firms in OECD countries, the adoption rate has increased from 15% in 2020 to almost 40% in 2024.
Triple Effect
The explosion of the environmental impacts of AI therefore comes from three effects that are reinforced:
First, an exponential growth of generative AI linked to the daily use of millions of users. This adoption is accelerated by ease of use (a cheap conversational interface that is easy to manipulate with instructions or prompts) and by an economic excitement of companies and states that drive the adoption of AI in an ever-increasing number of applications. Most of the time without asking the users for permission. A study of the research project Digital Limits shows that “never has a feature been pushed in such a short time, spatially, graphically, interactively and repeatedly in our websites, services and software.”
Second, with a complexity of AI models that are more versatile, larger, require more data and more computing power. With these so-called general purpose AI tools, you can as much generate a rap in the style of Eminem on the applesauce, as it can generate videos of Will Smith who eats spaghetti, as can be made as we can make summaries of meetings from voice recordings. The size of the LLMs was multiplied by 10000 between 2018 and 2023.
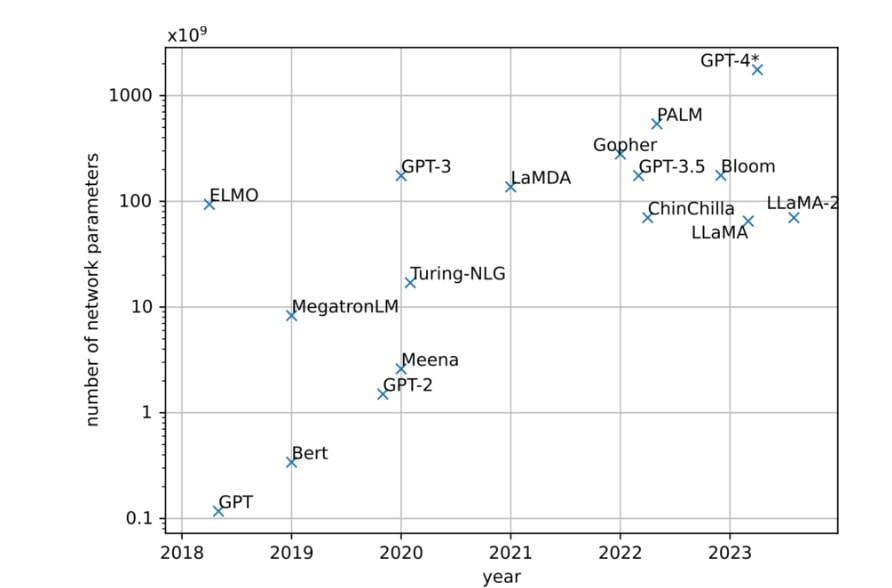
Third, an acceleration in the construction of data centers around the world to cope with the increased demand for generative AI services, causing local impacts on the electricity grid, on water, or pollution.
AI, more than technology
Finally, in this attempt to define what artificial intelligence is, it is essential not to confine oneself to a simple technical definition. AI is “a multidisciplinary field of research, a geopolitical issue, an industrial field, an advertising discourse and sometimes almost religious, a complex computer tool but also a global social phenomenon” as Thibault Prévost indicates in his book “The prophets of AI”.
The mention of the term intelligence gives the impression of an infallible system, in mastery, and participates in a mythification of technology. However, an AI system makes probabilistic calculations, errors, has many biases. The artificial term, on the other hand, tries to make us forget the underlying data created by humans, often extracted without their consent and the manual annotation work essential to their functioning.
Artificial intelligence is therefore never neutral: from the data on which it was trained, from its modeling, from the way it fits into society, it embodies and reproduces a worldview. Its development and impacts are intrinsically linked to the industry that took him out of the laboratory. “To understand how AI is fundamentally political, we need to go beyond neural networks and statistical recognition of forms and ask ourselves what is optimized, for whom, and who decides,” writes Kate Crawford. Let’s start with those who shape it.
Who is behind AI?
Thus, in order to understand the environmental impacts of AI, it is necessary to understand its industry and to grasp the economic and political balance of power that underlie it. AI players are structured around five essential links: data, models, computing power (compute), infrastructure, and applications and services.
Data is the raw material of AI, if a large amount of raw data exists in free license on the internet, digital giants (Meta, Google, Amazon, Microsoft) dominate the massive collection of data through their social platforms, search engines, cloud services and digital devices. In addition, there are personal data brokers (Experian, Equifax, …) or market (Nielsen, Acxiom, …), as well as many specialized players to clean, label, and annotate data for AI (Amazon Mechanical Turk, Scale AI, …) that employ an invisible army of precarious “clickworkers”.
AI models are developed by universities and private companies. In contrast, the most advanced models of generative AI are developed mainly (90% in 2024) by private giants Meta (Llama), Google (Gemini) or Alibaba (Qwen), or companies specializing in AI such as OpenAI (GPT), Anthropic (Claude), xAI by Elon Musk (Grok) or Mistral AI. Indeed, driving a model can cost in 2025 several tens to hundreds of millions of euros: what is completely inaccessible for universities or other companies and institutions. In addition, public AI research laboratories only have access to a few hundred chips of GPUs, when private laboratories have hundreds of thousands.
Computing power (compute) also requires a value chain with cloud companies in the first place: the market is dominated by Amazon (AWS), Microsoft (Azure), Google (GCP), IBM, Oracle or Alibaba. At the hardware level like the design of GPUs computing chips, NVIDIA overwhelms the competition with +80% of market share, followed by AMD and Intel. The production of these chips is carried out by the vast majority by TSMC (Taiwan Semiconductor Manufacturing Company) which produces +60% of the world’s semiconductors, while ASML (Netherlands) holds a complete quasi-monopoly on the EUV lithography machines essential for their manufacture.
The physical infrastructure of the calculation is based on the data centers. They are owned directly by tech giants (Meta, Microsoft, Amazon, Google, xAI, Alibaba) or rented from specialists such as Equinix or Digital Realty. Energy networks and suppliers are reorganizing around AI: nuclear (Constellation Energy, EDF, …), gas turbines (Shell, ExxonMobil, …), cooling and energy management systems (Schneider Electric, Vertiv, …), electrical transport and distribution. All of this infrastructure requires monumental investments of tens to hundreds of billions of dollars by investment funds, sovereign wealth funds or banks.
Applications and services are the latest link that makes AI accessible to end-users (individuals and businesses). At the consumer level, conversational interfaces like ChatGPT, Gemini, Claude or Perplexity dominate, while the APIs of these same companies allow developers to integrate AI into their own applications. Thousands of specialized startups are developing sectoral applications. Digital services companies (DSEs) like Accenture, Capgemini or CGI integrate AI into the information systems of large companies, and consulting firms like McKinsey, BCG or Deloitte sell “AI transformation strategies.”
The geopolitical dimension of AI
The dominance of private interests in AI is therefore everywhere: from model research and development, from software and hardware infrastructures to digital terminals and platforms. This asymmetry translates into considerable political influence: the tech sector is the one that spends the most lobbying in Brussels with 110 million euros per year – Google and Meta in the lead. This concentration of economic and political power around AI explains why environmental issues cannot be separated from these issues of power and democracy. The decisions that will determine the scale of the climate impact of AI – deployment and forced adoption of uses, energy system, allocation of resources, expansion of data centers – are taken by a handful of private actors according to their financial interests without democratic consultation.
This situation perfectly suits the states that, perceiving AI as a challenge of technological sovereignty in the race for global innovation, unroll the red carpet to these companies through massive public investments, tax exemptions and complacent regulations (such as Article 15 of the PLS law voted in France in June 2025 to encourage the expansion of data centers in France). Understanding this industrial and geopolitical reality is essential to understand the challenges of the ecological transition in the AI era.
AI is a financial abyss in search of profitability
However, in the big AI banquet, it’s not so easy to eat to your hunger. Investments are so monumental that it is difficult for all these players to achieve profitability and find a return on investment. OpenAI loses money every month (at least $1 billion in 2024) and every request on ChatGPT. Microsoft admits that generative AI does not generate enough economic value. Overall, despite the hundreds of millions of users, there is not enough revenue and use to justify the hundreds of billions invested in hardware infrastructure, AI models, and football star salaries of AI researchers.
To fill this economic bubble, AI companies have several ideas and strategies. Already, they are obliged to reduce costs as much as possible and to forcing to encourage adoption by all means. They seek to integrate advertising into generative AI apps (such as Snapchat or Perplexity) after sponsored posts on social media, get ready for sponsored responses on ChatGPT. Sam Altman, CEO of OpenAI, says he is reluctant, as the founders of Google or Facebook said, but is still preparing for it. Finally, they do above all what works best: sell a bright future, where the promises of a general AI that would save us from public debt, climate change, cancer and inequality, allow us to continue to attract financing. But behind the interest is cynically very economical, the definition of a general AI between Microsoft and OpenAI is also the one that would generate 100 billion profits.
Why is it important? Because for the moment in 2025, everything is going very fast. To anticipate environmental impacts, it is necessary to anticipate the evolution of uses. A lot of money is invested to cause the fastest acceleration possible, but the deployment of AI could also undergo many transformations and setbacks, if profitability does not progress.
The journey of a ChatGPT request
To simply understand the environmental impact of a generative AI, let’s try to break down what happens when you ask ChatGPT a question.
ChatGPT works through an LLM (Large Language Model): these recent algorithms in the large family of AI algorithms that have learned to predict the following word after learning about several billion examples. As their name suggests, these algorithms are “large”, and require a substantial computing power that is largely unattainable for computational chips that are found in our everyday tools (phone, computer, etc.). So we have to look for this power elsewhere, and it is in the “data centers” that we find it.
Data centers are large buildings that will store thousands of servers that will have to simplify two main functions:
- Storage: to store, manage and recover data – such as photos, videos, archives,..
- The calculation or compute: to process and analyze data on a large scale. It is in these specific infrastructures that the training and calculations of AI models take place, thanks to specialized chips such as ASICs, FPGA or GPU (Graphical Processing Unit or graphics cards) that are also found in computers for video games. These chips can carry out millions of operations in parallel, and in doing so will consume electricity and heat.
But before we could ask ChatGPT a question, we had to make the model. In the AI world, this is called training.
Training an AI model
Training involves showing a model millions of examples to model the data to reproduce patterns and then make accurate predictions about new data that he has never seen. Training is an intensive and time-consuming process that is carried out on specialized chips such as GPUs. A single high-end GPU (e.g. Nvidia’s H100 chip) has a power of about 700 watts, which is as much as a microwave. Advanced AI models require clusters (sets) of thousands of GPUs running in parallel in the same data center for reasons of communication efficiency between processors. They will concentrate a gigantic electrical power over a relatively short period.
The electricity consumption and emissions during the drive phase will vary drastically depending on the size of the model, the drive time (the number of hours of GPUs mobilized), and the carbon intensity of the electricity used at the location of the data center (at least 10 times higher in the United States than in France). Here are some examples:
| Model | Parameters | GPU hours | Consumption | CO2 emissions |
| BLOOM (2022) | 176B | ~1M hours | 433 MWh | 30 tCO2eq |
| Llama 3.1 8B (2024) | 8B | 1,46M hours | ~400 MWh | 420 tCO2eq |
| Llama 3.1 70B (2024) | 70B | 7M hours | ~1.9 GWh | 2 040 tCO2eq |
| Llama 3.1 405B (2024) | 405B | 30.8M hours | ~8.6 GWh | 8930 tCO2eq |
| GPT-3 (2020)* | 175B | 1.3 GWh | 552 tCO2eq | |
| GPT-4 (2023)* | ~280B | ~42 GWh |
*For BLOOM, electricity consumption is known, for the Llama models of Meta the power consumption is estimated according to the hours of GPUs and the declared CO2 emissions. For the PTG models, we have even less accurate data reported – however external studies have made estimates (IEA, Epochai)
To realize what this represents, when Meta uses 39 million hours of GPU in total for the different versions of Llama3.1, it is the equivalent of 4500 years of continuous calculation. This required more than 16 000 H100 computing chips, and 11 GWh of energy consumption. For GPT4, this required 3 months of calculation on 25 000 GPUs.
According to a study by Epoch AI (2024), the situation is accelerating: the power required to train AI models to continue to double every year despite hardware and software optimizations.
From a CO2 perspective, if you know your orders of magnitude, the emissions associated with training a model may ultimately seem rather small in relation to other industries. Already, the assumptions declared by the designers are often incomplete: Carbone4 increased for example the emissions of Llama from 9000 to 19000 tCO2eq taking into account a complete perimeter (not to mention the use). And to know the total impact of the training, it would be necessary to be able to add up all the trained models. But above all, it lacks a major element of the equation: usage.
In classical AI, it was traditionally the training phase that concentrated the most CO2 emissions because there were very few users and simpler algorithms. But with generative AI, the equation has totally reversed because the usages have been massified. Sasha Luccioni, a scientist and expert on AI environmental issues at Hugging Face, has established that around 100 million uses for this type of model, the inference phase becomes more energy-intensive than the initial training. This critical threshold is reached in just a few hours on ChatGPT, which now has at least 1 billion requests per day. For data centers, around 80% of electricity consumption is reserved for inference. In summary, this means that today for popular generative AI models, the environmental impact of daily use far exceeds that of their creation.
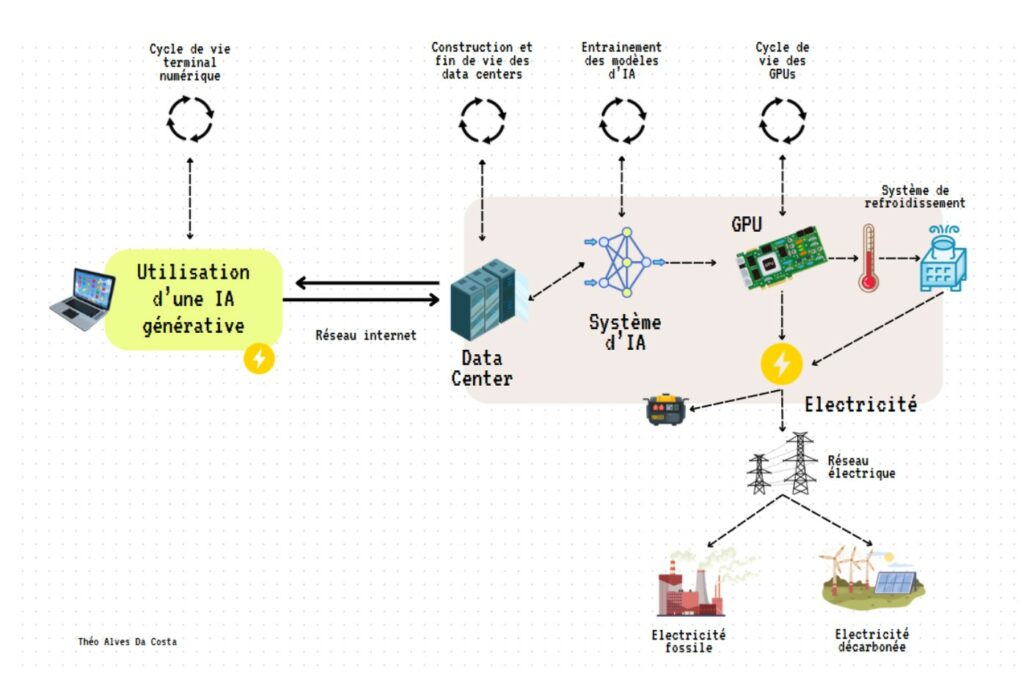
Inference for daily use
Once the model is trained, it can be used to ask a question:
- The question is sent from your computer or phone to the ChatGPT service. She will join a data center more or less far from your home. For example, if the calculation were performed in many data centers in Virginia or Oregon in the United States, it would cross an underwater cable under the Atlantic Ocean.
- The issue is handled by ChatGPT’s AI system in the data center’s servers – which also performs calculations of the millions of questions received simultaneously by users around the world, sometimes by pooling calculations to increase efficiency.
- To give an answer, ChatGPT performs a calculation. This calculation is carried out in the servers (and in particular the GPU graphics cards) of the data centers that will require electricity. This electricity can be supplied by the local electricity grid (at the location of the data center) or by additional backup generators, not connected to the grid. The carbon intensity of electricity will vary greatly depending on the modes of electricity generation used at the time and place of its use (coal, gas, renewable or nuclear).
- The completion of numerous calculations heats the servers. To keep them at an optimal temperature, the data center has a cooling system, which will also require electricity and water.
- The calculated response is then returned to the user and crosses the cables in the opposite direction to your user terminal.
Each element of this chain itself has a life cycle that brings its share of material environmental impacts – to manufacturing or the end of life – that is dissected in lower detail.
The problem of transparency
Little reliable data on the impact of AI
“A query on ChatGPT is equivalent to 10 searches on Google!” Since 2023, this figure has been hammered in the media and would symbolize the excessive energy consumption of AI. 75% of articles talking about the environmental impact of AI mention this statistic. In fact, we don’t know much about it. AI is in 2025 a very opaque industry: the giants of the industry do not communicate almost any reliable and verifiable data or information.
If we unfold the thread of this claim in all the media, a recent scientific publication has traced its genealogy: it comes from a remark made on the fly by John Hennessy, the president of Alphabet (parent company of Google), during an interview with Reuters in 2023. He said that “having an exchange with an AI known as a great language model probably costs 10 times more than a standard keyword search.”
This remark was then used as a basis to estimate “about 3 Wh by LLM interaction,” with the Google search figure being taken from a 2009 Google blog post that indicated 0.3 Wh of energy per search. This statement is problematic on several levels. First, John Hennessy has no connection to OpenAI or Microsoft (which provides the compute infrastructure for ChatGPT), so his comment is based on second-hand information. Then, Google’s number dates back more than 16 years, a time when web search was using keyword search techniques without a more energy-intensive AI model.
What is the impact of a ChatGPT query?
And we know even less the impact of a ChatGPT query that can be significantly different depending on the following parameters:
- Which version of ChatGPT is used – GPT5, GPT4o, GPT3.5, GPT4o-mini, o3-mini, o4, GPT4o-20250325? How many parameters are in the model used?
- How much information is ingested? Is that what you’re just asking a question of a hundred words? Or do you copy and paste 4 pages or add a PDF to your question?
- How much information is generated? A one-sentence response, or a report of about twenty pages?
- What features are used? Of the generation of text, or also of the generation of image or the ability to go for it on the internet?
The answer to these questions will determine the time required to carry out the calculation as well as the number of chips mobilized, and therefore the total electricity consumption for each of these uses. And to know the total environmental impact, it would also be necessary to know the number of users, the graphics card model used, the server optimizations carried out, the type of data center and its cooling system, its location or the carbon intensity of the local electricity grid.
But we do not know. There is very little data on the environmental impact of AI, as a new MIT study rightly reminds us. AI suppliers orchestrate this opacity and reveal almost no information for reasons of competitiveness (power consumption that can show economic and strategic choices or trade secrets), security (certain digital security standards require not to reveal the location of data centers), reputation (to mask ragging environmental impacts).
This opacity is not anecdotal. According to a recent analysis by Sasha Luccioni et al, 84% of the use of language models is done via models without any environmental transparency. In analyzing OpenRouter’s May 2025 data, the researchers showed that of the 20 most widely used models, only one (Meta Llama 3.3 70B) directly published environmental data. In terms of volume, only 2% of the use concerns transparent models on their environmental impact, 14% publish nothing but are open enough to do at least third-party energy studies, and an overwhelming majority of 84% of uses go through models without any environmental information. This situation has deteriorated since 2022 with the growing competition caused by ChatGPT.
Little data… and greenwashing
Note that during the summer of 2025 were published by Mistral and Google two studies to document for the first time some environmental impacts of a “median” request made on their mainstream AI. However, these studies are intentionally selective and do not give enough detail to compare and understand impacts while diverting attention from cumulative overall impacts by highlighting efficiencies and over-responsibilizing individuals.
In summary in 2025, even if it is possible to obtain approximations, we do not know the power consumption of a request on ChatGPT, the generation of a Ghibli studio image or a starter pack. As Sasha Luccioni said for Wired: “It amazes me that you can buy a car and know its consumption in the 100 kilometers, but that we use all these AI tools every day without having the slightest measure of efficiency, no emission factor, nothing.”
The Hypocrisy of Sam Altman
Sam Altman, CEO of OpenAI – the company that markets ChatGPT – said in June 2025 in its latest blog post “that an average request on ChatGPT consumes 0.34 Wh of energy, i.e. about what a furnace would use in just over a second, or what a high-efficiency light bulb would use in minutes” in an attempt to sweep away the criticism of AI energy consumption.
No precision, definition of scope or methodology, nor external audit allows to rely on this figure making it unusable but particularly effective in the factory of doubt. Paradoxically at the same time, he also said during a conference that “a significant portion of global electricity should be used for AI.” Let’s summarize: it does not consume anything, but at the same time we need all the electricity in the world.
What do we know about the consumption of a request?
While it is impossible to know about the consumption of ChatGPT at the moment, we still have some broader scientific studies on the environmental impact of generative AI. In particular, it is possible to measure the electrical consumption of “open weight” AI models, i.e. models that can be launched on one’s own servers and whose energy consumption can therefore be measured (with tools like CodeCarbon). This makes it possible to study different uses, and to approximate the orders of magnitude.
This is what researcher Sasha Luccioni did in 2023, in the reference scientific study “Power Hungry Processing” which for the first time encrypts the power consumption of a large number of open algorithms. She discovers that classifying a text (e.g. in ‘spam’) is a relatively harmless task. In the precise context of the study carried out in 2023, generating text is on average 25 times more energy consuming than classifying. Generating an image is on average 60 times more energy-intensive than generating text, about 1 to 3 Wh.
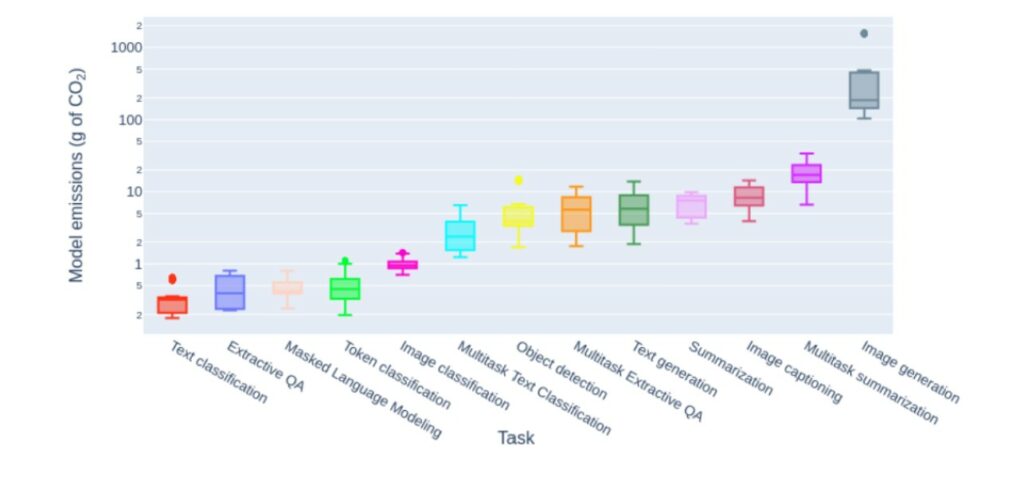
Since 2023 these figures have changed.
As for the generation of video, it explodes all the counters: according to the latest Energy & AI report of the AIE, a video of 6 seconds to 8 frames per second requires about 115 Wh, the equivalent of charging two laptops.
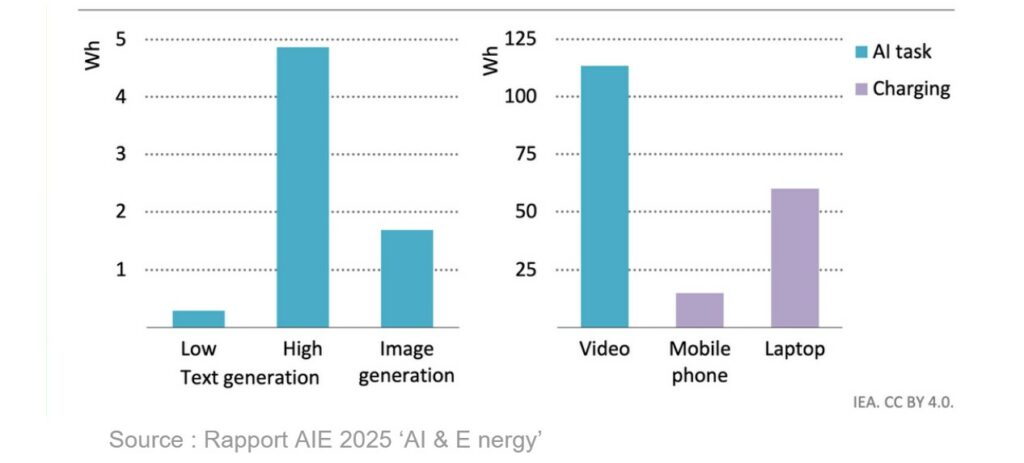
This prioritization of energy consumption according to use is important to understand the evolution of the environmental impact of AI and allow more accurate projections of the overall energy demand according to the adoption of each type of use.
Join the 40000 subscribers to our newsletter
Every week, we filter the superfluous to offer you the essential, reliable and sourced
Optimizing the electricity consumption of AI
Optimization techniques
To be able to truly understand the evolution of electrical uses and consumption, it is also necessary to take into account the optimizations that are made to make AI systems more energy efficient. Faced with the explosion of the energy consumption of AI and therefore operational financial costs, the AI industry is multiplying innovations to optimize the efficiency of its models. These techniques can be software, related to technological deployment, or hardware.
The first optimization family concerns optimization software techniques to reduce energy consumption in use that can be implemented by researchers and designers of AI systems. For example, quantization allows you to store information from an AI model with less accuracy. Pruning pruningis tantamount to removing unnecessary parts of a model of neural networks. Knowledge distillation allows to create lighter versions of the largest models by transferring some of the knowledge to a smaller, less energy-intensive model. The architecture of MoE (Mixture Of Experts) will make it possible to avoid mobilizing all the knowledge of the model each time. All these methods make it possible to reduce the electrical consumption by request (at inference) while maintaining almost the same quality of response.
The second family of optimization techniques is linked to so-called AI deployment systems, which is to make the model accessible and usable by millions of users, without bugs and without latency. For example, it is possible to process several requests at the same time (batch inference) to make the most of the power of computers to lower the energy cost per request. There are also automatic optimization software (specialized compilers) that intelligently reorganize calculations to avoid redundant tasks.
Finally, the third family of optimization applies to the hardware and computing infrastructures themselves, the graphics cards (GPUs) specialized for AI are faster than conventional processors while consuming less energy per calculation performed. Ultra-specialized chips for AI (such as Google’s TPUs or Groq LPUs) can provide more performance per watt consumed. Data centers have also gained efficiency thanks to the optimization of their PUE (Power Use Effectiveness) with different innovations ranging from improving cooling systems to energy optimization in real time.
Another idea that emerges is the use of lightweight models ( or SLMs). In theory some of these “hands-on” models, with a few million to a few billion parameters against hundreds of billions for behemoths, can run directly on smartphones or laptops, avoiding very energy-intensive calculations in data centers. However, there is no guarantee that these small models will completely replace the big ones: they are more likely to pile up with existing uses, creating new needs where there were none, such as AI assistants in every connected object or mobile application, while accelerating the implementation of GPUs computing chips in our phones and computers and therefore the obsolescence of digital terminals.
Despite all these undeniable technical advances, the global equation remains unbalanced. The computing power required to drive AI models has doubled every 6 months since 2012 and total power consumption continues to increase.
The Rebound Effects of AI
This phenomenon is therefore perfectly illustrated by what economists call “rebound effects”, recently analyzed in detail in the context of AI by Luccioni et al. (2025).
Direct rebound effects: when improving the efficiency of a product improves its accessibility, it can lead to an increase in consumption. For example for AI, the cost in € per word generated is divided by 10 every year for the same performance. Despite constant improvements in chip and algorithm efficiency, NVIDIA shipped 3.7 million GPUs in 2024, or more than one million additional units compared to 2023. At the same time, even if the energy efficiency of data centers has improved (even if the EUP is struggling to fall below 1.1), their total electricity consumption is exploding with more centres, larger centres and consuming more energy. These direct rebound effects are desired by the industry to make their investments profitable by increasing usage.
The multiple indirect rebound effects of AI (uses in other carbon sectors, new manufactured products, etc.) will be the subject of a second article to be published later.
The DeepSeek case
The iconic case of rebound effect is that of the Chinese AI model DeepSeek-R1. Launched on January 20, 2025 by the Chinese company DeepSek, this open source AI model has caused a sensation and caused Nvidia’s shares to fall by 17% in a single day. Unlike the media announcements that present this Chinese reasoning model as an energy revolution, the first independent tests are actually much more nuanced. Although DeepSeek has indeed reduced its training costs thanks to optimization techniques such as the mix of experts (MoE), this theoretical efficiency comes up against a major rebound effect during daily use.
One of the other problems is an architecture of the AI model popularized by DeepSeek (in particular its R1 model), based on the chain-of-thought“chain-of-thought”, a technique that allows the model to break down complex problems into intermediate reasoning steps before giving its final answer. The tests conducted by the MIT Technology Review show that this approach is ultimately more energy-intensive to use: DeepSeek tends to generate much longer responses than traditional models: on average on 40 queries tested, the model consumed 87% additional energy simply because it produced extensive reasoning texts.
These results echo recent academic research on the energy impact of reasoning models. The publication “The Energy Cost of Reasoning” demonstrates that these so-called “reasoning” models can multiply energy consumption by a significant factor – up to 97 times more in some cases – because models generate on average 4.4 times more words than their traditional equivalents, sometimes reaching 46 times more in extreme cases. As researcher Sasha Luccioni warns: “If we widely adopt this paradigm, the energy consumption of inference would explode.”
The Direct Impacts of Artificial Intelligence
Now that we’ve explored what AI is, which is behind its development, the peculiarities of generative AI with what we know and what we don’t know, the difference between usages, and possible energy optimizations, we are ready to analyze all the environmental impacts related to AI at the global and local level of data centers.
Thirst for electricity
“Many people predict that electricity demand for [AI] will increase from 3% to 99% of total output… or an additional 29 gigawatts by 2027 and 67 gigawatts more by 2030.” This phrase was uttered by Eric Schmidt, former CEO of Google before Congress, like the delusions of grandeur of the tech giants. What is it now?
As we have seen, data centers consume a lot of electricity, both to carry out the calculations during the training and inference phases, but also to cool the servers.
The power consumption of data centers is exploding because of AI
According to the latest report from the International Energy Agency (IEA), data centers account for 1.5% (415 TWh) of global electricity demand in 2024. AI would represent around 10% of this demand (the rest used for data storage, streaming, cryptocurrencies, etc.).
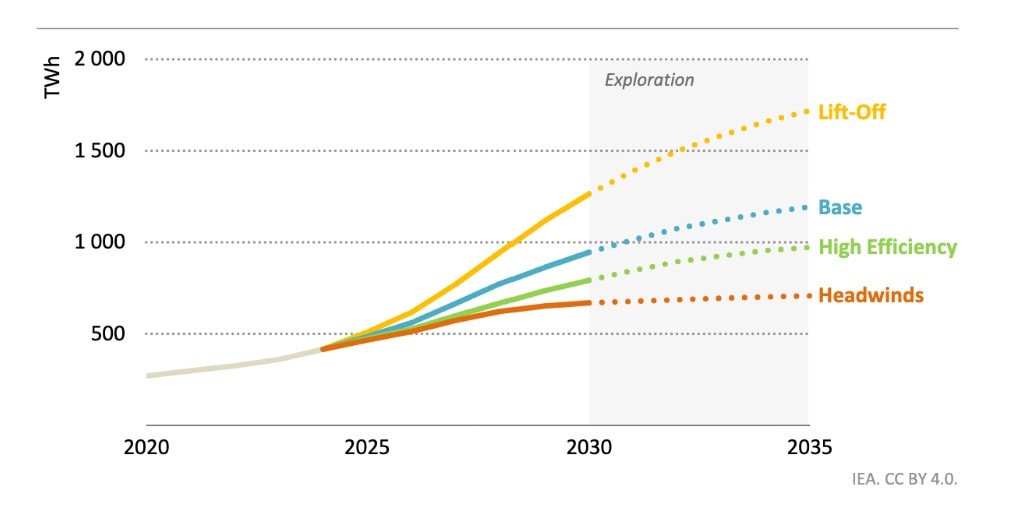
But even more than the absolute figures, it is the dynamic that is dizzying: in its basic scenario, the IEA predicts that data centers will reach 3% (975 TWh) of global electricity demand by 2030. This represents an increase of 15% on average per year, 4 times faster than the increase in electricity consumption in all other sectors.
In the United States, in 2030, the demand for electricity from data centers could account for more than the demand for electricity brings together aluminum, steel, cement, chemical and other intensive industrial goods in electricity. This increase is largely driven by the development of generative artificial intelligence and associated terminals, which under scenarios is expected to account for at least more than 50% of the electricity consumption of data centers, which represents an acceleration for AI from at least between x5 and x10 compared to 2022.
Geographical disparities in electricity consumption
This average global electricity consumption actually hides huge disparities, as data centers are highly concentrated geographically, which increases local usage conflicts around resources.
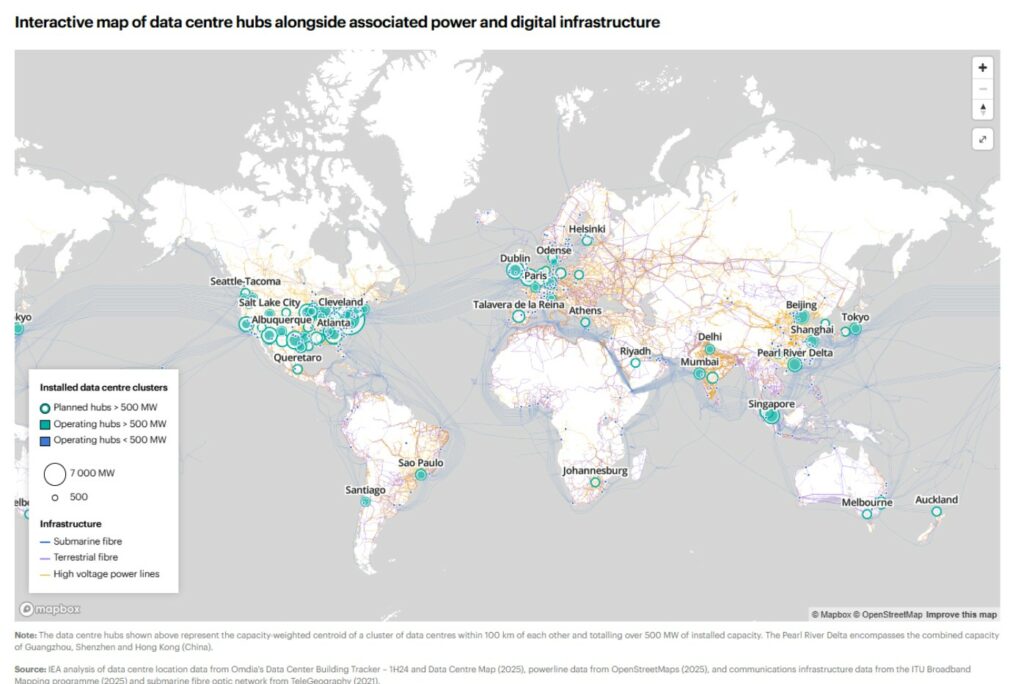
There were about 8000 data centers worldwide in 2024. Hundreds more have been announced since. The map above highlights the world’s large clusters: the United States, Asia Pacific with China in the lead, and Europe in third place. The most concentrated region in the world is Northern Virginia in an area dubbed the “Data Center Alley”, thanks to very much settlement-friendly regulations, a historically central area in internet development and low-cost electricity.
In Malaysia, dependent on more than a third of the coal for its electricity production, the city of Johor Bahu, a former fishing village, is transformed into a data center hub, and is nicknamed the “Asian Virginia”. Microsoft and Amazon are investing heavily in the region. In Europe, Ireland has the most data centers in 2024, and it is no coincidence that Ireland is a real European tax haven and has put in place an aggressive policy to welcome data centres.
Conflicts of use related to electricity
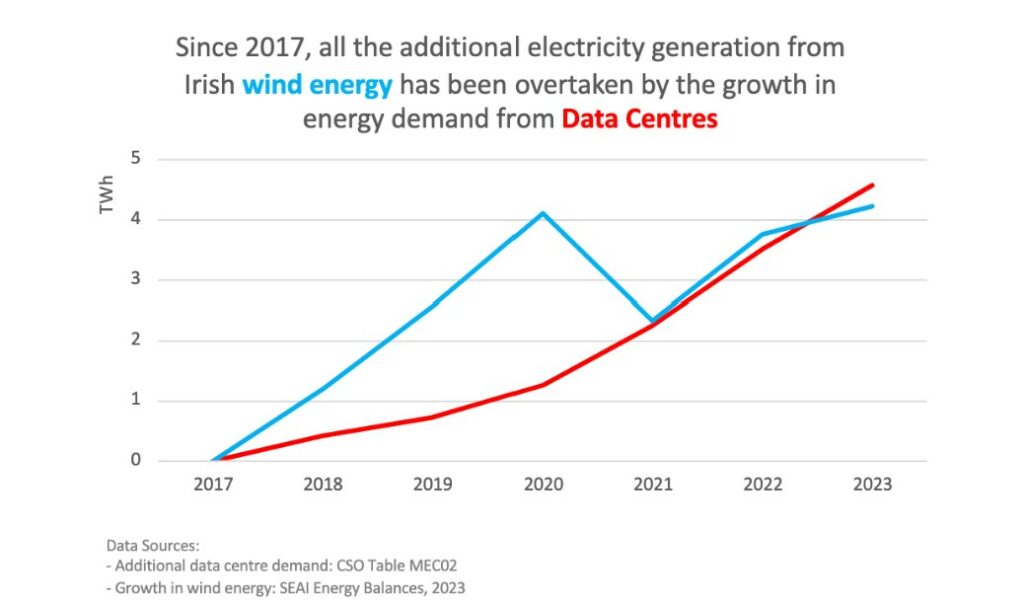
This concentration generates conflicts of use, even in France where there are conflicts of use in Marseille, where the demand for electricity from data centers competes and penalizes the electrification of public transport and ferries, which contribute to local pollution. In Ireland, data centres consume 21% of the country’s electricity and people must live with the spectrum of potential blackouts as centres grow.
In Ireland, the electricity demand of data centres has exceeded the growth in capacity of wind power, preventing them from substituting other fossil uses.
Local impacts related to electricity
Moreover, data centers are not flexible: they do not support power outages that lead to a total shutdown of the servers. For safety, they are therefore systematically equipped with batteries and generators (the vast majority of which operate in oil) to take over in the event of a power outage. The latter must be tested in all cases at least a few times a month to check their operation, which increases CO2 emissions and air pollution.
For example, the “PAR7” data center of the Courneuve, owned by Interxion France, has 8 generators, each engine is more than 6 tonnes and is equivalent to that of a “liner crossing the China Sea” according to a survey by Usbek and Rica in 2017. 280 000 liters of fuel oil are stored, and preheated permanently to be able to start at any time. In Ireland, EdgeConneX’s data center backup generators have emitted an additional 130 000 tCO2eq from 2017.

Finally, the figures mentioned above do not include the electricity necessary for the life cycle of a data center such as the environmental footprint necessary for the manufacture of IT equipment or those of the manufacture of a center.
Impacts on the electricity distribution and transmission network
The rise of AI is powering the entire distribution and electrical transport system. It is not only the number of data centers that is increasing, but also their power. A few years ago, the centres demanded a power of a few dozen MW. In 2025, with the explosion of AI, they represent several hundred MW. The largest data centers announced will have 5GW power – the equivalent of producing a large nuclear power plant. This very rapid demand concentration in specific geographical areas creates voltage points on the current electricity grid.
Network connection bottlenecks are now a physical limit to the development of AI. The latest IEA Energy & AI report summarizes, for example, (Table 2.4) that wait times to connect new data centers now extend to 7-10 years in some U.S. jurisdictions, with extreme cases such as the Netherlands where deadlines can reach 10 years.
These tensions result in immediate technical impacts and the risk of shortages in the medium term. AI workloads present particular challenges for network operators because of their distinct characteristics: AI drive generates sustained and high power consumption with periodic peaks and drops, while inference can cause rapid fluctuations in demand depending on what users do.
Operationally, data centers are already causing malfunctions of the electrical network (Box 2.10, IEA): overheating of electrical equipment by overload, dangerous voltage fluctuations that can damage appliances, disruptions in the quality of the electric current, and network instabilities causing variations in frequency. When a network disruption pushes a data center to switch over its backup power supply, it abruptly removes a massive load from the network, which can cause voltage or frequency changes and potentially trigger cascading cuts.
This situation forces electricity operators and states to make massive investments to modernize the electricity grid, with their own environmental impacts. For example, this involves the construction of new high-voltage lines, the installation of more powerful transformers – all of which require concrete, steel and rare metals, generating additional carbon emissions.
These investments and operational costs for the grid sometimes even translate into another social injustice: an increase in the electricity bill for the communities present on these electricity grids. In the eastern United States, the monthly bill was able to increase in the summer of 2025 from an additional $10 to $27 per month in the face of increased demand for AI.
CO2 emissions, the freewheel
CO2 emissions related to the carbon mix of electricity
With regard to the demand for electricity when using the data centre, CO2 emissions are highly dependent on the carbon intensity of the electricity consumed.
The sharp increase in electricity demand with the very rapid deployment of AI has worrying consequences for the climate because it is ensured by a connection to means of rapid energy production to be implemented and largely carbon.
Thus, many coal-fired power plants around the world are seeing their closure date postponed, endangering our climate goals. This is the case, for example, of three plants with a capacity of 8.2 GW (in Mississippi and Georgia) to meet the demand of data centers or a coal-fired power plant in Nebraska, to meet the needs of Meta and Google.
In addition, the creation of new gas-fired power plant projects is justified by the need to provide energy to data centres. The Open Source “Global Energy Monitor” database has identified the installation of 44 GW of new gas projects worldwide only to meet the demand of data centers, including 37 GW in the US. For example, ExxonMobil announced in December 2024 the opening of a 1.5 GW gas plant exclusively dedicated to data centers.
The question of the “behind-the-meter”, of electricity not connected to the grid
Tech giants, which face the limits of energy availability and regulatory time to grid connection, are developing alternative solutions such as the direct installation of electrical generation infrastructure adjacent to data centers, thus circumventing the constraints of the public grid and its collective governance mechanisms, but using carbon energy.
Although they rely heavily on geothermal or nuclear (Amazon invests in SMR start-ups, small modular nuclear reactors, and the OpenAI founder relies on nuclear fusion), these facilities will not be ready for several years, and in the short term the choices are made to gas turbines.
Zoom on xAI in Memphis
This is precisely the strategy adopted by Elon Musk with xAI in Memphis for his data center “Colossus” – proudly presented as “built in 19 days”. To meet its immediate energy needs, xAI has deployed 15 obsolete gas turbines already operating without public notification or regulatory oversight since the summer of 2024. According to an operating permit recently filed with the Shelby County Health Department, xAI plans to operate these turbines without interruption from June 2025 to June 2030. According to The Commercial Appeal, this equipment each emits 11.51 tonnes of hazardous air pollutants per year, exceeding the annual 10-tonne ceiling set by the EPA for a single source.
This infrastructure is part of an unequal geographical context. It is located near Boxtown, a historically black district, already overwhelmed by chronic industrial pollution. Shelby County is currently rated “F” for its smog levels by the American Lung Association, with a local cancer rate four times higher than the national average and a life expectancy reduced by 10 years compared to the rest of Memphis.

The fact that GAFAMs are beginning to generate their own energy is part of a growing opacification of the sector on their real impacts and is very bad news for democracy.
The IEA estimates that emissions from electricity consumption from data centers represent 180 million tonnes (Mt) today, and will increase to 300 Mt in the base scenario by 2035, and up to 500 Mt in the mass adoption scenario of AI, experiencing one of the most important sectoral growths. (let us once again say that these emissions are partial: they only take into account the highest value of the high-value sectoral components)
At the local level, seeing a data center arrive in its territory may mean that it can no longer meet its climate goals when a plan may have already been underway. In Frederick County, Maryland, a new 2GW data center powered by gas turbines ultimately makes it impossible for the local government’s GHG emission reduction trajectory.
Google, Microsoft, Meta. What about the programs of the digital giants?
What we see today is an explosion of the emissions of the tech giants in years light of the commitments of neutrality: Google has multiplied by 2 its broadcasts since 2019; 2023 Microsoft has increased them by 30%, and is therefore 50% above its stated objective.
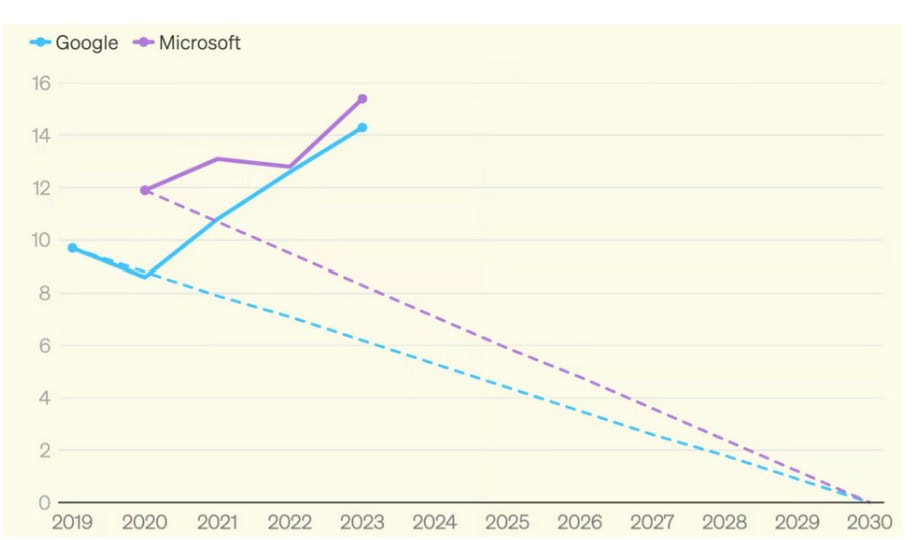
But these figures represent only part of the emissions, because the giants play with the rules of current carbon accounting to erase some of their emissions related to energy consumption (scope 2). Everything is played out in the definition of the method of calculating energy consumption, between a “location based” approach and a “market based” approach:
- Rental based : This method calculates greenhouse gas emissions according to the real energy mix of the network to which the company is connected. It reflects the physical reality of the electricity actually consumed.
- Market based : This method calculates greenhouse gas emissions based on the nature of the electricity supply contract. It allows to count to zero the electricity purchased from renewable sources, regardless of the physical reality of consumption. The market mechanisms used are:
- Renewable Energy Certificates (RECs): these are low-carbon electricity purchase options that can be used up to one year after the date of purchase, anywhere in the world. They can therefore be very far from the actual consumption of the company. For example, data centers that turn at night with a strong mix of coal and gas as in Virginia can be “erased” by the purchase of a certificate attached to renewable energy produced 2 months later during the day in Nevada.
Green energy purchase contracts (PPAs), among which we distinguish:
– physical PPPs, which involve the actual delivery of electricity from the renewable generation site to the buyer’s consumption site. Places of production and purchase are often geographically closer. Physical PPPs are therefore considered to be instruments with high environmental integrity, of better quality than CERs.
– Virtual PPPs (vPPAs), which are financial contracts, without physical electricity delivery. As with RECs, there is not necessarily spatial and temporal synchronization between production and consumption.
The “Market based” accounting was initially developed to encourage players to invest in new capabilities and decarbonize the electric mix. Unfortunately, the use of market instruments (RECs, virtual PPAs, etc.) does not necessarily have a direct impact on the actual decarbonization of the electric mix. At the same time, it allows large companies to display a zero accountant in the emissions related to their energy consumption, and thus to eliminate the physical reality of their consumption. ‘
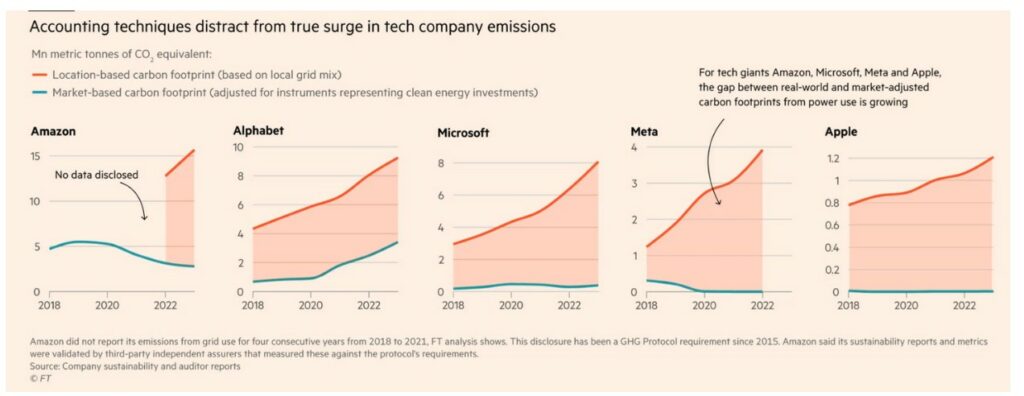
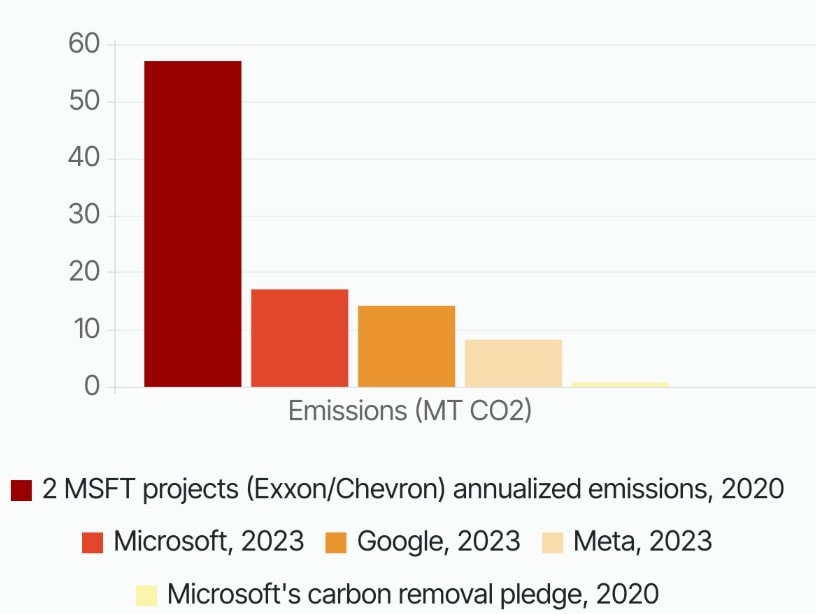
If we take the example of Microsoft which declares 16 million tons of CO2 in 2023 (first graph of the section) in “market-based”, we must add 8 million tons of additional CO2 related to its electricity consumption-(2nd graph) to obtain its real emissions in “location-based”, i.e. 50% more than what is declared.
Water consumption
The use of water from data centers
Data centers are big water consumers. Although this consumption is again difficult to estimate, it can be cut into several levels:
- direct water consumption to cool the servers. The cooling of the servers is mainly done by air (air conditioning or outdoor air recovery systems) or by liquid (air spraying, liquid diffused directly on the components). The method used will greatly influence water consumption. The less water the cooling technique requires, the more energy it consumes and vice versa. The new large Nvidia clusters (racks > 40kW) use “direct liquid cooling”, a cooling technique where the liquid is brought directly into contact with the components to be cooled. This consumes virtually no water but raises many questions about the impacts and recycling of this glycol water.
- consumption indirectly via the manufacture of electricity that powers data centers. With regard to electricity, the amount of water taken and consumed is strongly dependent on the mode of production (in the order of consumption): hydroelectricity, nuclear, coal, and gas take and consume large amounts of water to run the turbines or cool the systems, where solar or wind require virtually no withdrawal.
This graph represents the water taken and the water consumed by the data centers according to the different stages of the life cycle projected until 2030 by the IEA.
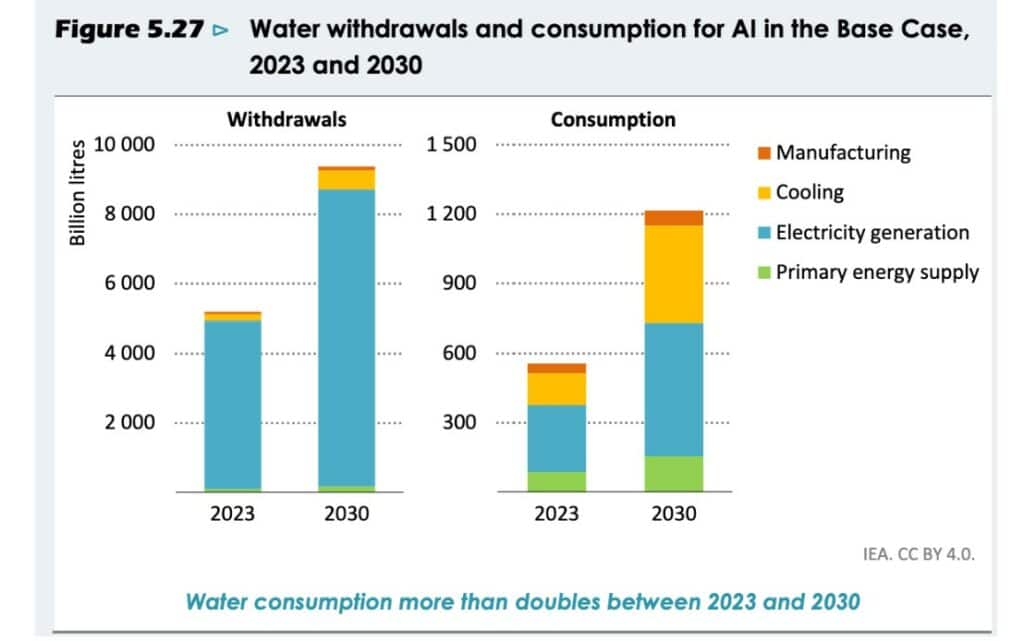
Cooling : to the cooling of the servers.
Electricity Generation: water required for the production of electricity consumed by the data center.
Primary Energy Supply: water required for the primary energy used in the center (excluding electricity)
Sources: IEA modelling and analysis based on Harris, et al. (2019), Hamed et al. (2022), IEA (2016), Lei, et al. (2025), Lei and Masanet (2022), and Shehabi, et al. (2024)
The International Energy Agency expects to double the water consumption of data centers by 2030 in its base scenario, reaching 1 200 billion litres in 2030. There has already been a rapid demand in recent years, especially in the United States. Between 2019 and 2023, water consumption at Virginia’s data centers increased by more than 60%, according to figures from water suppliers obtained by the Financial Times.
Conflicts of uses related to the water consumption of data centers
The impacts of water consumption will depend a lot on the concentration of the centers and the hydrological situation of the area: the more water stress the area, the more even a low sample disturbs the environment. Because even when the water is taken without being consumed, it is not returned to the same place and therefore generates conflicts of use. In the U.S., this goes so far as to prevent people from being housed: in June 2023, authorities in Maricopa County, Arizona, which houses two Microsoft data centers, have cancelled permits to build new homes due to lack of groundwater and “extreme dryness” in the area, according to a Guardian investigation. Since 2020, it has also been in conflict with agriculture as in Taiwan, where farmers are forced to deflect the available water to the chip manufacturing company -TSMC.
A large part of the projects under development are in already arid areas: in Microsoft’s 2023 CSR report, it is discovered that 42% of its water comes from ‘water stress zones’ while having increased its water consumption by 34% compared to the previous year. As for Google, 15% of its water consumption comes from areas in tension according to its 2024 report. In Aragon, Spain, an already arid region where Amazon plans to open three new data centers, the company has just asked the regional government for permission to increase its water consumption on its existing centers by 48%.
These tensions are compounded by the fact that data centers are now mainly connected to drinking water. For example, Google uses drinking water for more than 2⁄3 of its consumption.
Although some criteria explain these choices of location (easier heat evacuation in a dry climate, larger sunshine) the lack of consideration of the scarcity of the resource and its impact on the environment is worrying.
“Water positive”, the new trendy greenwashing
At the same time, GAFAMs continue to make new commitments, such as becoming ‘Water positive’ (Amazon, Google, Microsoft by 2030). The notion of neutrality at the scale of a company was already problematic with carbon, neutrality being scientifically valid only at the scale of a country or the world. When it comes to water, this claim of “neutrality”, or even “positivity” is even more misleading because the impacts are more localized and complex than for CO2 emissions: “compensating” water consumption can in no way cancel the impacts on populations and ecosystems where it is consumed. In addition, evaporating water or taking it from one place by restoring it to another disturbs the balances and the water cycle. These commitments also do not take into account the water consumed or taken to generate the electricity consumed by the data centers and are also very difficult to verify. The Guardian reports in its large water survey that Amazon plans to help farmers use water more efficiently… through AI.
Abiotic resources for the manufacture of equipment and building: dependence on metals and the chemical industry
Metals, chemistry and electronic waste
AI infrastructure depends on a large number of materials, commodities and resources that are entangled in global supply chains.
No AI without servers, without chips, and especially without GPUs. However, these chips themselves require electricity, water, abiotic resources to be manufactured.
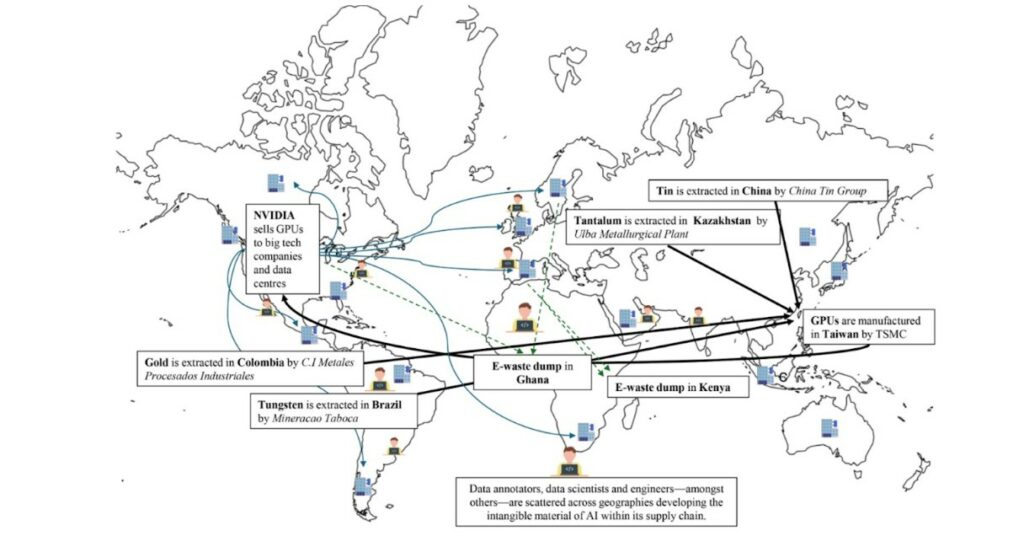
This illustrative graph, taken from a paper by researcher Ana Valvidia, highlights the international value chain of AI. It begins with mining: tin in China, tantalum in Kazakhstan, gold from Colombia, Tungsten from Brazil, etc. All these metals are received by Taiwan Semiconductor Manufacturing Company (TSMC) to manufacture GPUs, which are designed by the American company NVIDIA, in quasi-monopoly with more than 85% of the market share. These GPUs are then sent to data centers around the world. On average, they have a lifespan of 5 years.
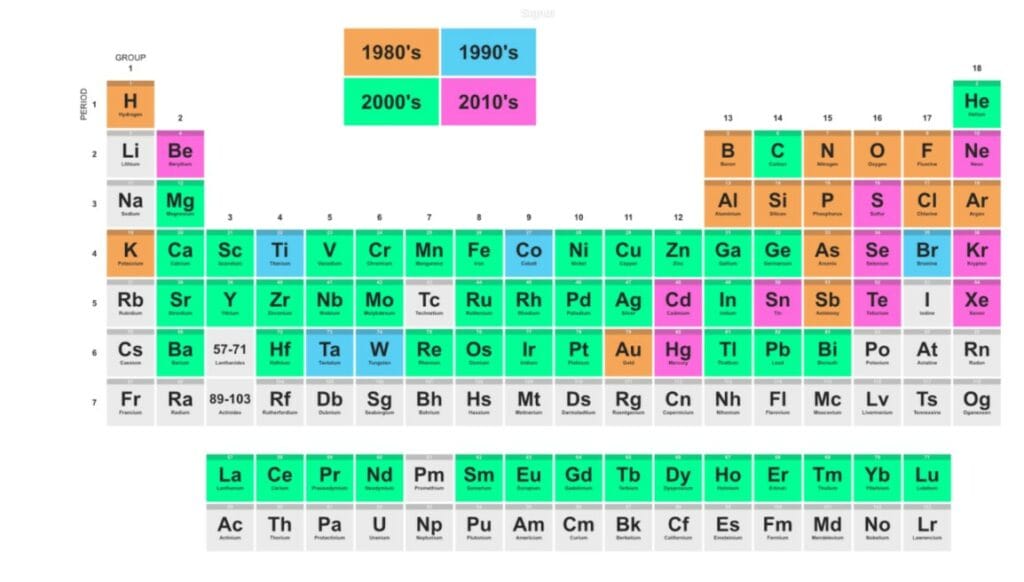
The diversity and quantity of metals mobilized by digital has increased significantly since the 80’s as traced in the graph below. Since the creation of semiconductors, chips have evolved by being smaller and more efficient. The needs of AI have created new challenges: a need for increasingly pure metals, which leads to an increase in energy consumption, the ecological footprint and increased dependence on the chemical industry, as shown by researcher Gauthier Roussilhe, specialist in digital impacts. These impacts are poorly known and difficult to quantify, but they undeniably increase in absolute value, despite efficiency gains and generate strong local pollution in countries where extraction is established. Moreover, they perpetuate the logics of neo-colonial exploitation of the resources and work of the countries of the Global South.
Pollution and toxicity
Electronic waste
The ultra-sophisticated components used in data centers contain an exceptional amount of toxic materials (lead, cadmium, mercury) in a small space. Only 22% of e-waste is currently recycled properly. The rest often ends up in informal landfills mainly in the global South, where thousands of workers decommission the obsolete GPUs of the West with bare hands, exposing themselves to contamination up to 220 times above European thresholds. A study published in Nature Computational Science estimates that generative AI could generate up to 5 million tonnes of additional e-waste by 2030, in addition to the 60 million tonnes produced today. This acceleration is explained by three factors: the exponential energy needs, the rapid evolution of specialized equipment that imposes constant upgrades, and the commercial wars of semiconductors that force some actors to deploy twice as many less efficient chips.

Noise
Noise is the most immediate nuisance: inside a large center, the servers reach 96 dB(A), the level of a chainsaw, while outside the constant buzzing of cooling systems carries hundreds of meters away.
Air pollution
Especially due to back-up diesel generators that emit up to 600 times more nitrogen oxides than modern gas plants. According to a study by UC Riverside and Caltech, even used at only 10% of their capacity in Virginia, they already cause an additional 14 000 cases of asthma per year. The projections for 2030 are dizzying: the expansion of AI could cause 600,000 cases of asthma and 1,300 premature deaths per year in the United States, with health costs of US$20 billion – more than the impact of the 35 million California vehicles.
Local pollution
Another pollution concerns certain cooling systems that can use fluids with PFAS (“eternal pollutants”), chemical molecules that are almost indestructible in the environment. These local pollutions are an additional pattern of environmental injustice since data centers are most often located near already vulnerable communities.
Conclusion
Artificial intelligence is material. To understand its impacts, you have to go up your value chain that mobilizes metals, water, energy, land. But more than a static image, we must appreciate its trend: the tech giants are shifting us towards an uncontrolled acceleration of AI, causing a race to expand data centers around the world, insidiously forcing it into a growing number of our everyday tools, transforming our interactions and perception of the world. The current growth seems incompatible with our climate goals. In addition, it strengthens mechanisms of domination: U.S. and Chinese companies operate more than 90% of the data centers that other companies and institutions use for their AI work and only 32 countries in the world, mostly located in the northern hemisphere, have data centers specialized in artificial intelligence.
A fundamental issue remains to be addressed. Beyond the direct impacts listed above, we must question the purpose of the uses that AI serves, what it allows and accelerates. Explore how it fits into our current economy and how it strengthens its ultra-carbon nature. And this is not going in the right direction: the tech giants have established very special relations with the oil and gas sector. Amazon with BP; Google with TotalEnergies and Gazprom; or recently Mistral with TotalEnergies (read an analysis here). It is once again very difficult to estimate the additional emissions generated by these partnerships, but the few available figures are already edifying. For example, Microsoft’s AI-use emissions on just two projects with Exxon and Chevron account for 300 percent of Microsoft’s reported emissions in 2023, according to whistleblower Holly Alpine. These AI-facilitated emissions are not confined to the Oil and Gas: advertising targeting, fast-fashion, mining, etc.: so many activities and uses that accelerate our productive system.
In addition, AI recommendations also play a fundamental role in the climate: by shaping our opinions and promoting certain content more than others, they help to invisibilize topics while spreading misinformation about others. Climate change is one of the most exposed topics to online misinformation. This helps to slow adherence to transition measures, accentuates the polarization of our societies and puts our democracies at risk.
The reality is very far from the techno-solutionist discourse of tech barons who claim that any fight against climate change will be impossible without AI to decarbonize our economy. In doing so, they never mention that a majority of their revenue comes from advertising and the fossil fuel industry. Climate-using AI algorithms, mainly using specialized and relatively energy-sound machine learning techniques, serve as an alibi to justify a large forward leak.
Their promises, systematically formulated on the conditional, are a decoy. To date, there is no comprehensive study to support these claims. The positive impacts of AI development remain deeply hypothetical and overestimated, without taking into account the contexts in which technologies are developed and the social upheavals they generate. The negative effects are largely undervalued and masked.
These promises divert us from a questioning of the sobriety of our uses.
Finally, these discourses are part of a new political context, where tech giants embrace Donald Trump’s far-right ideas. In doing so, they put their technology at the service of its political project: scientific obscurantism, total denial of global warming, authoritarian state that combines its power on Big Data. We will address all of these issues in a future article.